Optical Character Recognition (OCR)
Optical Character Recognition (OCR) converts images of printed text into machine-readable text. Incode’s proprietary OCR extracts data from global IDs and documents with 25% more accuracy than open-source OCR.
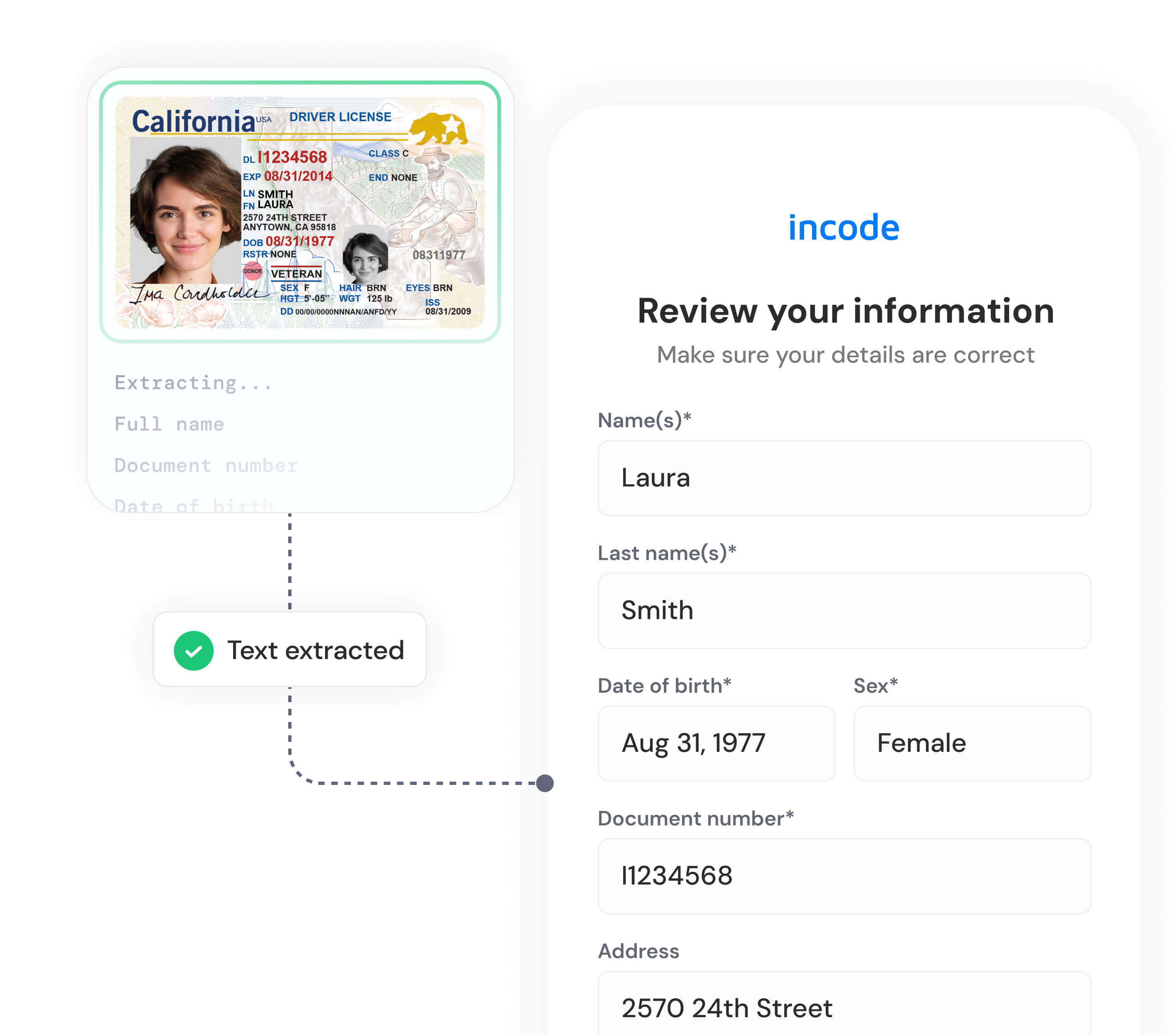
Top companies switch to Incode for our proven impact on fraud protection and growth












Where other OCR falls short
Unlike Incode, much of the industry uses open-source OCR
Struggles with Complex Documents
Non-standard layouts, poor image quality, and varied formatting trip up other OCR systems.
Data Discrepancies
Results in false negatives, user frustration, and expensive manual checks by humans.

User drop-off
Slower processing slows down onboarding, causing users to drop-off.

Intelligent OCR built for any document, anywhere
Image Optimization
Optimizes images for OCR, even if poorly captured.
Global Language Support
Extracts text in Latin, Non-Latin, Cyrillic, Arabic, Asian characters, and more.
Unparalleled Accuracy
Meticulous analysis of the entire ID with lightning-fast processing, including non-text components
ID Pattern Recognition
Accurately identifies and extracts data from diverse, global ID types with near-perfect accuracy.
Adaptable Layout Detection
No rigid templates – our OCR learns the structure of your documents, even if they change frequently.
Customized Solution
With each scan our OCR continually adapts to the unique IDs seen by your business, for unrivaled accuracy.
Incode’s OCR offers faster, error free verification for improved completion rates

Optimized User Experience
Reduce drop-offs by streamlining the verification process with reliable data extraction.
Accelerated Onboarding
Faster, more accurate data extraction minimizes errors and reduces friction.

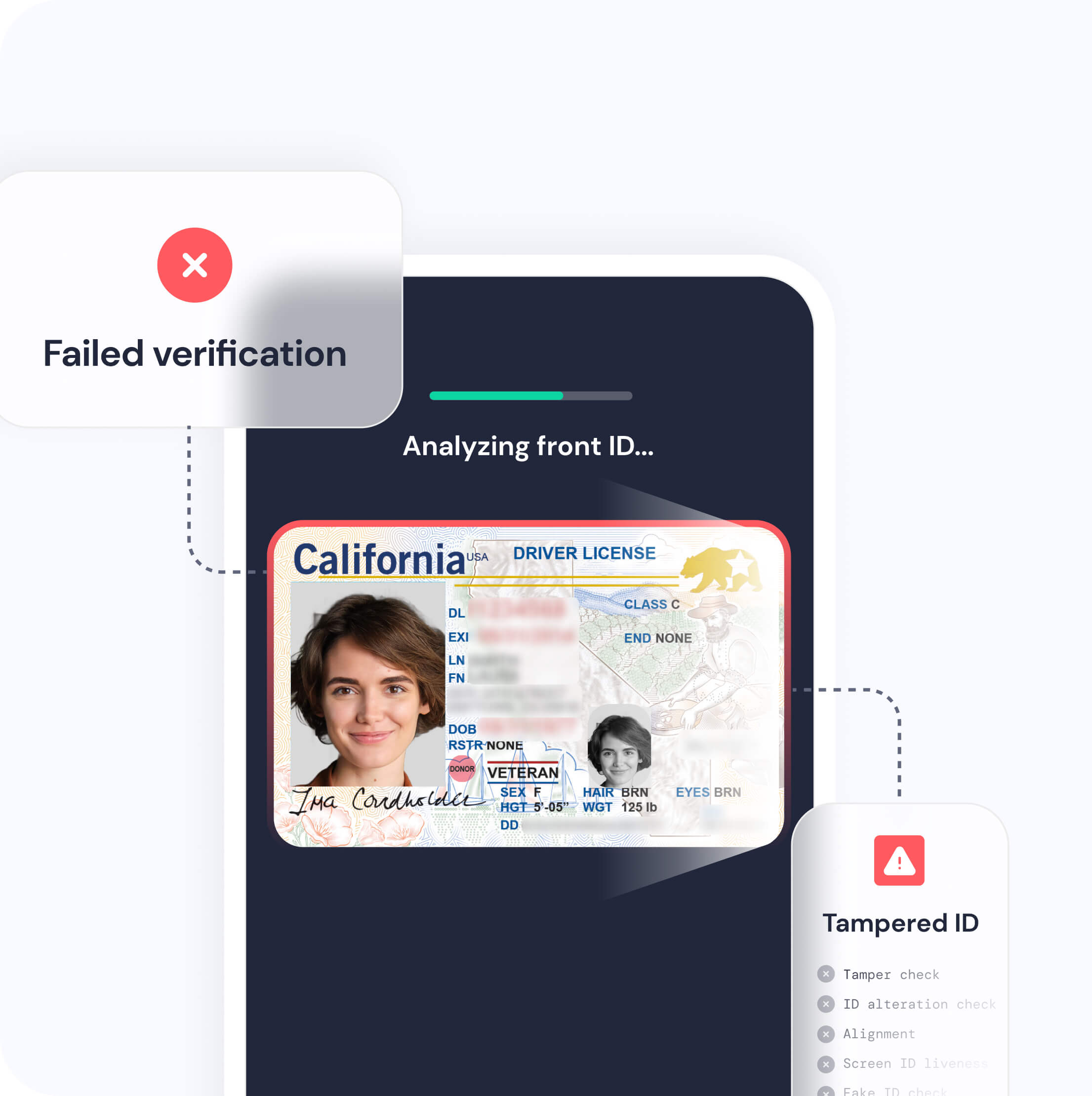
Precision Fraud Detection
Leverage AI-driven image analysis to detect counterfeit and altered IDs.
Regulatory Compliance (KYC/AML)
Ensure accurate data capture for effective and efficient compliance with industry regulations.