Optical Character Recognition
Incode’s in-house developed Optical Character Recognition (OCR) technology extracts and processes data from thousands of global identity document types, ensuring fewer data discrepancies and enhanced fraud detection.
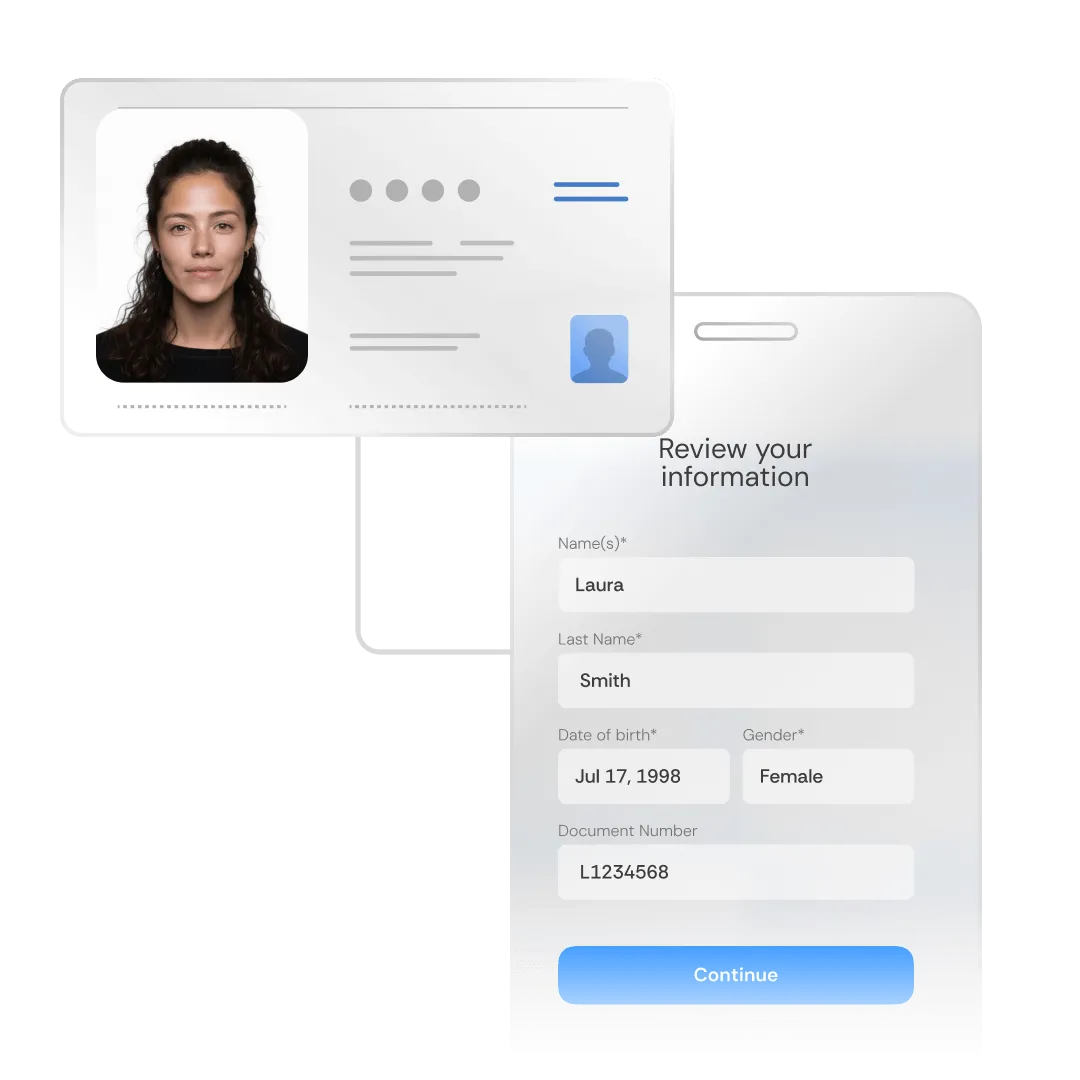
Incode’s in-house developed Optical Character Recognition (OCR) technology extracts and processes data from thousands of global identity document types, ensuring fewer data discrepancies and enhanced fraud detection.

.svg)
.svg)
.svg)
.svg)

.svg)
.svg)

.svg)
.svg)
.svg)
.svg)

.svg)




Many general-purpose OCR technologies on the market fail to meet the requirements of fast-moving businesses.

Basic OCR cannot handle diverse documents worldwide because it lacks ML models trained on large, varied ID datasets.


Fonts with various shapes and styles often confuse basic OCR, leading to errors unless the system is trained to handle them.
.avif)

Handling multiple languages challenges OCR, especially when scripts use many characters, diacritical marks, or different reading directions.
.avif)
.svg)
Special symbols, like those on US bank checks, are often missed by general OCR systems that are not trained to detect them.
.avif)
.svg)
OCR struggles with poor contrast, cluttered layouts, and overlapping objects. It can also misread similar documents such as permits and licenses.


OCR that relies on third parties adapts slowly, often misreading government documents with new elements the models do not recognize.

.svg)
Poor lighting, shadows, stains, or tears can reduce even advanced OCR accuracy and reliability.
.avif)

Basic OCR struggles with blurry or distorted images, often misreading characters and shapes.
.avif)
Built in-house, Incode OCR processes 4.9K+ identity documents worldwide. It adapts to low-quality images, complex fonts, and unique symbols with accuracy and scale.
Unlike general tools, Incode OCR is designed to capture and process data from thousands of identity documents worldwide.
We use advanced ML models that adapt to document variations like fonts, diacritics, symbols, and barcodes for stronger OCR results.
.avif)
Our in-house technology uses a 2-stage algorithm to accurately extract text from 4.9K+ documents in 190+ countries.
.avif)
We improve accuracy so your organization meets regulations and protects itself from costly penalties or reputational loss.
.avif)
Our ML-driven capture SDK reviews and validates multiple frames within seconds, surpassing human performance.

Incode’s capture SDK improves image quality through smart frame selection, real-time feedback, and automatic ID orientation detection.
.avif)
Our full air gap solution enhances security in special use cases, protecting against unauthorized access, data leaks, and cyberattacks.
.avif)
We design pipelines for specific document types, enabling fast adaptation to new formats and updates.
.avif)
Trial error-free verification with Incode’s intelligent technology.
This guide showed how Incode’s in-house developed OCR uses ML to improve the accuracy of identity verification.
Candidate proposal
Refinement
Our ML models handle all the heavy lifting, making every user interaction feel effortless. By delivering improved results, even in suboptimal conditions, we save our users time and minimize the need for manual intervention.
Features such as smart frame selection, automatic ID orientation detection, and real-time feedback help to ensure our process is straightforward and easy to navigate. By simplifying and speeding up the process, we boost completion rates and drive conversions.

Incode OCR outperforms open-source and general purpose solutions. With ongoing benchmarking and bias analysis, we ensure consistent accuracy across document types, languages, and visual conditions.

Our OCR delivers higher accuracy across diverse document types, outperforming general-purpose solutions in key fields such as name, address, birthplace, document number, expiry date, and machine-readable zones (MRZ).
Verified reviews, certifications, and customer stories show the impact of Incode’s technology.







.avif)
Request a demo and experience faster, more accurate OCR for your business.
%20(1).avif)







.svg)


.png)